Classifying Civil Service Jobs using Large Language Models and Mixed-Integer Programming
3 minute read
September 2, 2024
On October 28, 1949, President Harry S Truman signed into law the Classification Act of 1949. For U.S. civil servants, the statute among other things:
Established the principle of providing equal pay for substantially equal work,
Provided a definition of each grade in the General Schedule, and
Directed the Office of Personnel Management (OPM) to prepare standards for agencies to use in placing positions in their proper classes and grades.
There are currently over 1,500 different job classification in the U.S. Federal Civil Service. When a federal agency creates a new position, they are required by law to classify that position into one of these 1,500 classifications based on guidance published by the OPM. There are a number of factors that must be considered when classifying a new position including: job duties and worker qualifications.
These standards are great, and I’m sure provide a lot of equity between government employees. However, imagine the amount of effort required by all the federal agencies to manually classify each new position, especially when you consider that there are over 7,000,000 federal employees. What’s more, federal employees make up just a fraction of all government employees. When you consider all of the state, county and municipal jurisdictions, each of which may have a different classification system, that’s an enormous amount of work to manually classify all those jobs.
The BP3 AI practice is currently working with a state agency who creates about 150 job posting postings per month and are required by state law to classify each job posting to as one of approximately 1,000 state civil service classifications. Using their current process, it takes approximately 45 minutes for an administrator, who is familiar with the state’s classification guidelines to classify each job. That’s about 300 hours per month, or 1350 hours per year of manual effort.
In most cases, the primary inputs for classifying a new job posting are the individual job duties and how they compare to the job duties for standard job classifications. Automating the classification process can be accomplished by combining two different type of Artificial Intelligence:
comparison of embedding vectors generated by a large language model (LLM)
selection of the overall best job classification based on aggregated pair-wise semantic similarities of job duties using mixed-integer programming.
Probably the best way to illustrate this process is with an example. Imagine the county zoo is looking for a new zookeeper.
Upon review of the job duties from the classified ad, we see that there are 8, including the catch-all one of “Other duties as assigned”. The first thing we need to do from a solution standpoint, is compare each one of these new job duties to all of the job duties of all the standard civil service job classifications. To make these comparisons, we’ll use a natural language processing technique called “embedding vectors”.
Embedding vectors are a way to represent words or phrases as numbers in a way that captures their meaning and context. It’s like giving each word its own unique code that helps computers understand the relationships between different words. This makes it easier for computers to work with language and understand the meaning of the words in a more human-like way. For example, imagine we want to compare the meanings of different words, in this case, House, Puppy, Dog and Cat. By representing each word as a 2-dimensional vector, we can compare the distances between each vector. The distance between two vectors, as denoted by the dashed lines, can be used to understand the similarity between the two words. The shorter the distance, the more similar the meaning of the words.
Using large language models (LLM’s) we can compute embedding vectors not only for words, but for entire sentences and even paragraphs. By comparing the distances between two embedding vectors of two different paragraphs, we can use these distances to compare the similarity of meaning between the two paragraphs.
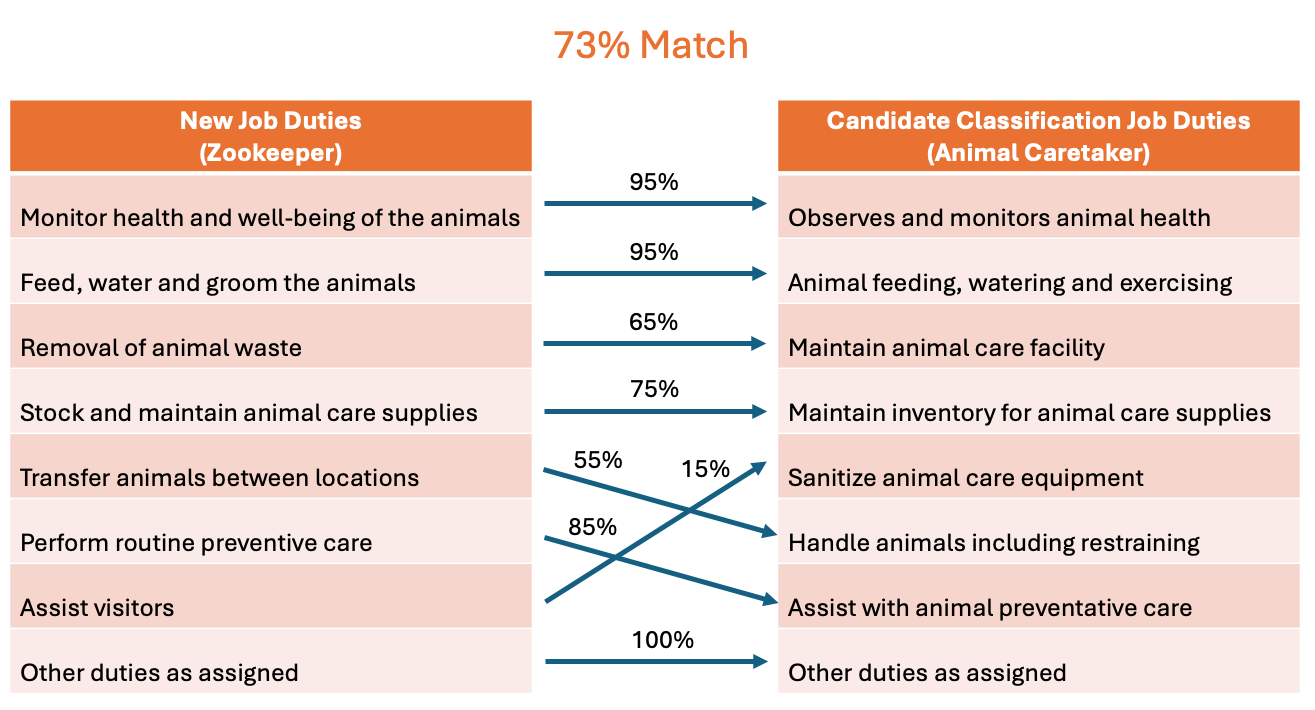
Going back to our zoo keeper job posting, we can use embedding vectors to compare the job duties for our zoo keeper with another civil servant position like an animal caretaker.
Overall, this is a pretty good match, 73%. Certainly better than other positions like an accounting specialist, which has an overall match of only 27%.
Now that we can compare individual job duties for similarity, we need a way to find the overall closest matching civil service job classification based on the best pair-wise match of job duties from our new job (Zookeeper) and all the job duties of each individual civil service job classification. This problem can be formulated and solved as a mixed-integer programming problem, which falls within another area of artificial intelligence called operations research.
Using mixed-integer programming, we can express the problem as a series of multi-variable equations with an objective function for minimizing the overall semantic distance between the new job duties and the job duties of the selected job classification, along with a set of constraints that ensure that all the duties of the selected civil service job classification are considered in the overall match.
More specifically, we can formulate the problem as follows:
From an implementation standpoint, we built the classifier using Azure serverless function apps, blob storage, OpenAI’s Ada-002 embedding model, and the open source mixed-integer programming solver COIN. By using a serverless architecture, we can pretty much scale the application to any kind of volume, and from a cost standpoint, we only pay for what we use, so it’s very cost efficient.
We see this application as a great example of what we are seeing in the automation space where multiple artificial intelligence techniques can be combined to solve a single problem.
Unlocking the true potential of AI requires understanding its multifaceted nature. Discover the diverse skills and applications that make up AI with...